KCZI fromat zdjęć
KuczaRacza
Wersja formatu: 7
Wersja dokumentacji: 1.0
Spis
Wprowadzenie
KCZI to format pliku rozwijany jako test różnych metod kompresji stratnej zdjęć. Stworzony przez KuczaRacza. W przyszłości będzie dalej rozwijany. Kompatyblność wsteczna nie będzie zapewniona, gdy wyjdzie kolejna wersja formatu. Aktualnie rozwijanym kodekiem jest kczi-cpp. Stary kodek wspiera wersję 6 KCZI i nie będzie aktualizowany. Kod w tym kodeku jest ciężki do utrzymania, wynika to z tego, że koncepcja na format wielokrotnie się zmieniała. Chętnie zobaczę nowe implementacje KCZI, jak i pull requesty do kodeka kczi-cpp. W razie niejasnośći w dokumentacji, proszę się skontaktować i postaram się poprawić dokument, aby wszystkie koncepty były jasne.
KCZI struktura pliku
Struktury występujące w każdym Kczi
Ogólna struktura pliku
| pole | typ | wielkość |
|---|---|---|
| Magiczne bajty | u8 | 4B |
| Wersja | u32 | 4B |
| Wielkość pliku | u64 | 8B |
| Wielkość danych po dekompresji | u64 | 8B |
| Dane skompresowane ZSTD | u8 | Wielkość skompresowanych danych - 24B (B) |
Struktura danych skompresowanych ZSTD
| pole | typ | wielkość |
|---|---|---|
| Nagłówek | Struktura(stała wielkość) | 24B |
| Regiony | Struktura(zmienna wielkość) | zmienna i ilość |
| Słowniki(opcjonalne) | Struktura(zmienna wielkość) | zmienna wielkość i ilość |
Struktura nagłówka
| pole | typ | wielkość |
|---|---|---|
| szerokość | u16 | 2B |
| wysokość | u16 | 2B |
| format pixeli | u8(enum) | 1B |
| największa głębokość regionu w drzewie | u8 | 1B |
| wielkość bloczków | u16 | 2B |
| współczynnik redukcji kolorów | u16 | 2B |
| jakość | u16 | 2B |
| ilość regionów | u32 | 4B |
| ilość słowników | u32 | 4B |
| współczynnik kwantyzacji DCT na początku macierzy | u16 | 2B |
| współczynnik kwantyzacji DCT na początku końcu | u16 | 2B |
Struktura regionu
| pole | typ | wielkość |
|---|---|---|
| Pozycja X | u16 | 2B |
| Pozycja Y | u16 | 2B |
| Szerokość | u16 | 2B |
| Wysokość | u16 | 2B |
| Głębokość w drzewie | u8 | 1B |
| Indeks słownika | u16 | 2B |
| Długość danych bloczków | u32 | 4B |
| Dane bloczków | u32 | Długość danych pikseli(B) |
| Długość danych typów bloczków | u32 | 4B |
| Dane typów bloczków | 2b(enum) | Długość Danych typów bloczków |
Struktury występujące w kczi w trybie indeksowanym
Struktura słownika
Dla RGB
| pole | typ | wielkość |
|---|---|---|
| Wielkość | u8 | 1B |
| Kolory | RGB(3B) | 3B * wielkość |
Dla RGBA
| pole | typ | wielkość |
|---|---|---|
| Wielkość | u8 | 1B |
| Kolory | RGBA(4B) | 4B * wielkość |
Struktura bloczków
Interpolacja (ID 0)
| pole | typ | wielkość |
|---|---|---|
| Pixele | indeks(1B) | 4B |
Pełna rozdzielczość (ID 1)
| pole | typ | wielkość |
|---|---|---|
| Pixele | indeks(1B) | Wysokość * Szerokość |
Struktury występujące w kczi w trybie yuv
Struktura bloczków dla YUV
Interpolacja(ID 0)
| pole | typ | wielkość |
|---|---|---|
| Pixele | YUV(3B) | 12B |
Subsampling(ID 1)
| pole | typ | wielkość |
|---|---|---|
| Pixele | YUV420(3B) | Wg. wzoru |
Długość: (floor(w/2) * floor(h/2) * 6B) + ((w*h - floor(w/2) * floor(h/2) * 4) * 3B).
Gdzie W to szerokość bloczka, a H to wysokość bloczka
DCT (ID 3)
| pole | typ | wielkość |
|---|---|---|
| Współczynniki | i16 | Wg wzoru |
Długość: w * h * 2B * 3
Gdzie W to szerokość bloczka a H to wysokość bloczka
Struktura bloczków dla YUVA
Interpolacja(ID 0)
| pole | typ | wielkość |
|---|---|---|
| Pixele | YUVA(4B) | 16B |
Subsampling(ID 1)
| pole | typ | wielkość |
|---|---|---|
| Pixele | YUVA420(3B) | Wg. wzoru |
Długość: (floor(w/2) * floor(h/2) * 10B) + ((w*h - floor(w/2) * floor(h/2) * 4) * 4B).
Gdzie W to szerokość bloczka a H to wysokość bloczka
DCT (ID 3)
| pole | typ | wielkość |
|---|---|---|
| Współczynniki | i16 | Wg wzoru |
Długość: w * h * 2B * 4
Gdzie W to szerokość bloczka a H to wysokość bloczka
Informacje o obu trybach
Wszystkie dane są zapisane w little endian. Każdy plik KCZI zaczyna się 4 bajtami informującymi o formacie i wersją formatu. 4 bajty to znaki ASCII tworzące napis KCZI. Po nich jest u64 wskazujący wielkość pliku kczi, następnie jest kolejne u64. Podaje ono wielkość danych skompresowanych ZSTD po dekompresji. Jest to bardzo przydatne, ponieważ można stworzyć bufor na zdekompresowane dane i uniknąć realokacji.
Nagłówek
W skompresowanych danych jest nagłówek pliku kczi. Zawiera on informacje na temat wielkości zdjęcia, formatu czy trybu użytego do enkodowania jego. Pole "Format pikseli" oznacza, jakiego trybu użyto, i jaki jest format pikseli. Wartości enumu:
- 2 - Tryb indeksowany z alfą
- 3 - Tryb indeksowany bez alfy
- 4 - Tryb YUV bez alfy
- 5 - Tryb YUV z alfą
Regiony
Kolejną rzeczą specyficzną dla kczi są regiony. Każdy region ma zapisane swoje bloczki, pozycje i głębokość. Pozycje regionów są tworzone przez podział wejściowego zdjęcia na pół, gdy zostaną spełnione warunki. Warunki zależą od implementacji enkodera. Cały proces dzieje się rekurencyjnie, czyli raz podzielone na pół zdjęcie nadal jest dzielone dopóki regiony powstałe w wyniku podziałów spełniają warunek na kolejny podział. Przykładowe zdjęcie z pokazanym podziałem:

Z każdym podziałem zwiększa się głębokość obszaru. Od niej zależy, jakiej wielkości bloczki będą w regionie.
Bloczki
Bloczki są najważniejszym elementem kompresji w formacie. Są zapisane w tablicy z lewej na prawo, a następnie z góry na dół. Nie mają stałej wielkośći w bajtach. Każdy z nich ma jeden z 4 dostępnych typów. Działanie bloczku zależy od trybu, inne w indeksowanym, inne w YUV/YUVA. Dekodowanie będzie opisane niżej w tekście. Typ zależy od 2 bitów w tablicy danych typów bloczków, znajdującej po tablicy bloczków (patrz tabelki). Aby dostać informacje o typie, można posłużyć się takim kodem:
//block_pos to pozycja bloczka w tablicy w regionie
uint8_t bitshift = (block_pos % 4 * 2);
uint8_t type = (blocks_types[pos / 4] & (3 << bitshift)) >> bitshift;Bloczki są kwadratowe z wyjątkiem bloczków na krawędzi regionu. Wielkość bloczku oblicza się w następujący sposób:
uint32_t block_size =
(1.0f - region_depth/ (float)max_depth) * e_args.block_size;//max_depth jest zapisany w nagłówku pliku
block_size = (block_size < 8) ? 8 : block_size;
block_size /= 2;
block_size *= 2;Jeżeli wielkość regionu nie jest podzielna przez wielkość bloczku, to bloczki na krawędzi należy powiększyć w taki sposób, aby pokrywały pozostałe piksele. Przykład :
uint32_t block_size_y = region.y - block_size * (block_in_column * block_size);Zdjęcie przedstawiające podział na bloczki. Widać jak zachowują się na krawędziach regionu oraz jak różnią się wielkością, W zależności od regionu, są pokolorowane według typu. Ciemnoczerwone regiony są bloczkami interpolowanymi, a jasnoczerwone są bloczkami zapisanymi w pełnej rozdzielczości.

Tryb indeksowany
Tryb indeksowany jest prostszym sposobem enkodowania danych w formacie KCZI. Każdy kolor jest przedstawiony jako indeks w tablicy kolorów. Tablica kolorów jest zapisana w słowniku. Pole indeksu słownika w strukturze regionu wskazuje, który słownik wybrać. Przykładowo region
struct Region {
uint16_t x = 0;
...
uint16_t dict_index;
...
uint8_t * pixels;
...
};
struct Region r;
r.dict_index = 4;
r.pixels[5] = 4;oznacza, że kolor szóstego piksela jest zapisany w piątym elemencie tablicy wewnątrz piątego słownika w pliku. Słowniki są zapisane na końcu pliku, jak opisano w tabelkach. Jeden słownik może być używany przez wiele regionów.
Bloczki
ID 0 interpolacja
Bloczek ma w sobie 4 elementy, są to kolory na rogach bloczku. Wnętrze bloczku należy wypełnić, odpowiednio interpolując wartości. Nie ma jednego zdefiniowanego algorytmu interpolacji, jest to kwestia implementacji dekodera.
Kolejność rogów:
- lewy górny
- prawy górny
- prawy dolny
- lewy dolny
uint8_t color = block[2]; //color ma kolor prawego górnego roguID 1 pełna rozdzielczość
Piksele są zapisane z lewo na prawo, z góry na dół, jako indeksy do słowników.
Tryb YUV/YUVA
Ten tryb jest zaprojektowany pod większe zdjęcia. RGB jest przekształcane na YUV. W tym trybie, słowniki nie występują.
Bloczki
ID 0 Interpolacja
Zapisane są 4 piksele. Odpowiadają one wartością kolorów na rogach bloczku. Bloczki należy wypełnić, interpolując te wartości. Algorytm interpolacji jest zależny od implementacji.
ID 1 YUV420
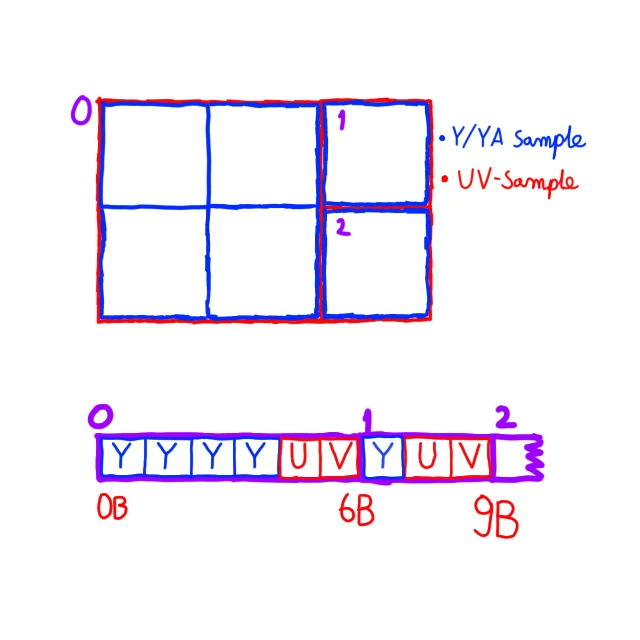
Zapisuje bloczek z dwa razy mniejszą rozdzielczością U i V, gdy Y i A są pełnej rozdzielczości. Najpierw są zapisane 4 próbki Y i A, jeśli występuje w zdjęciu, po których zapisana jest jedna próbka U i V. Całość zajmuje 6B bez Alfy i 10B z alfą na kwadraciku 2x2px. Gdy bloczek ma nieparzystą liczbę pikseli, n.p. 4x5, oraz nie da się podzielić na kwadraty 2x2, żeby próbować odpowiednio, piksele na prawo, lub/i na dole, które są na końcu bloczka z nieparzystymi wymiarami, są zapisywane ostatnie - z lewej do prawej, z góry na dół.
ID 3 DCT
Bloczek jest zapisany jako współczynniki funkcji cosinus o różnych częstotliwościach. Więcej informacji można znaleźć na Wikipedii. Przykładowy kod pokazujący zamianę jednego kanału bloczku pikseli na współczynniki
for(uint32_t y = 0;y<size_y;y++){
for(uint32_t x = 0;x<size_x;x++){ //pętla wykonjuje się dla każdego piksela
for(uint32_t m = 0;y<size_y;m++){
for(uint32_t n = 0;x<size_x;n++){ //pętla wykonuje się dla każdego współczynnika
//piksel musi mieć wartość pomiędzy -1.0 a 1.0
wsploczynnik[m * size_x + n] += pixel[x + size_x * y] * cosf((M_PI/size_x)*(x+0.5f)*n)*cosf((M_PI/size_y)
* (y+0.5f)*m)/(size_x * size_y);
}
}
}
}Wynikiem będzie macierz współczynników z wartościami pomiędzy -1.0 a 1.0. W kczi, w celu lepszej kompresji, przekształcane są one na 16-bitowego inta. Po konwersji wartości <-1.0 , 1.0> na short int'y, kolejnym krokiem zmniejszającym ilość stanów oraz zwiększającym kompresje jest kwantyzacja. Polega ona na stworzeniu macierzy wartości, które stanowią podstawę do generowania macierzy znajdującymi się w nagłówku pliku. Przykładowy kod generujący macierz:
for(uint32_t y =0; y < size_y; y++){
for(uint32_t x= 0; x < size_x;x++){
float distance = pow(((i * i + j * j) / (float)(sizex * sizex + sizey * sizey)), 2);
//start jest zapisany w nagłówku jako "współczynnik kwantyzacji DCT na początku macierzy"|
//end jest zapisany jako "współczynnik kwantyzacji DCT na końcu"
matrix[x + y * size_x] = start + (end - start) * dist;
}
}Po dzieleniu wartości współczynnika przez wartość macierzy oraz zaokrągleniu po stronie enkodera:
dct[n] = roundf(dct[n] / martix[n]);Po stronie dekodera należy pomnożyć współczynniki przez macierz. Enkoder może ustalić dowolne współczynniki początku i końca macierzy. Warunkiem jest to, aby liczba na początku była mniejsza od liczby na końcu.
W pliku kczi, współczynniki nie są zapisane rzędami i kolumnami, nie jest to optymalne rozwiązanie. Używa się pętli zig-zag pokazanej na ilustracji. Pozwala ona zwiększyć wydajność bezstratnej kompresji. 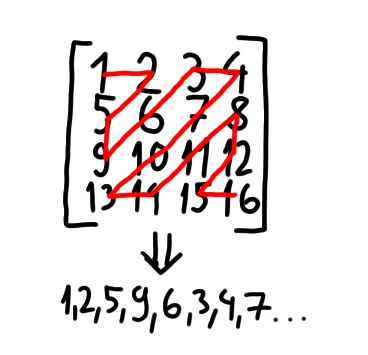
Na obrazku widać tablicę ułożoną rzędami i kolumnami. Czerwona linia pokazuje kolejność w pętli zig-zag. Na dole widać, jak liczby są ułożone w tablicy po takim przekształceniu.